Mety Ho An'ireo Fiteny Rehetra Any Azia Atsimo Ny Rindrambaiko OCR (Optical Character Recognition) An'ny Google



Dingana mandeha tsikelikely amin'ny fampiasàna ny rindrambaiko Famantarana Endri-tsoratra an'ny Google (OCR) izay afaka mahazaka ny ankamaroan'ireo fiteny Aziatika Tatsimo. Sary an'i Subhashish Panigrahi, nampiasàna malalaka ny lisansa CC-by-SA 4.0.
Ankehitriny ny rindrambaiko Optical Character Recognition (OCR) nataon'ny Google dia miasa ho anà fiteny maherin'ny 248 manerana izao tontolo izao, tafiditra amin'izany ny ankamaroan'ireo fiteny Aziatika Tatsimo be mpampiasa, sady mora ampiasaina no mety amin'ny 90% ilay izy ho an'ny maro amin'ireo fiteny ireo.
Tena nitondra soa betsaka ho an'ny fianarana ny teny ny rindrambaiko OCR, nanampy tamin'ny fisintonana izay rehetra lahatsoratra avy any anaty sary vita printy—ary indraindray aza dia sora-tànana, izay manokatra varavarana ho amin'ireo lahatsoratra tranainy, sora-tànana sy ny sisa.
Ketan Pratap ao amin'ny NDTV Gadgets manoratra hoe:
Azon'ireo mpampiasa atao ny manomboka mampiasa ny fahaizamanaon'ny OCR amin'ny alàlan'ny fampàkarana antontan-taratasy natao amin'ny endrika PDF na sary ho ao amin'ny Drive ary avy eo manindry ny havanana amin'ny totoziny eo ambonin'ilay antontan-taratasiny ao amin'ny Drive mba hosokafan'ny Google Docs ilay izy. Aorian'ny safidiny, misy lahatsoratra iray miara-misokatra eo anilan'ny sarin'ilay lahatsoratra niaingàna, izay azo avoaka printy. Marihan'ny Google fa tsy takiana amin'ireo mpampiasa akory ny hamaritra ny fiteny voarakitra ao anatin'ilay antontan-taratasy satria ny OCR ao amin'ny Drive ihany no hamaritra izany ho azy. Misy ao amin'ny Drive ho an'ny Android ihany koa io fahafahan'ny OCR ao amin'ny Google Drive io.
Ao amin'ny Twitter, marobe ireo mpampiasa no niarahaba ny fahatongavany sy nankalaza mihitsy aza ity zava-baovaon'ny Google ity :
Optical Character Recognition #OCR in Google Drive recongnizes many indic languages including #Kannada give it a try http://t.co/99UkCJQ6gb
— Omshivaprakash (@omshivaprakash) August 28, 2015
Mamaky mari-pamantarana teny maro ny #OCR ao amin'ny Google Drive. Isan'izany ny #Kannada Mba andramo
@shylobisnett if you have access to a scanner, you can do OCR through google drive. works a bit faster.
— Whet Moser (@whet) August 27, 2015
Raha manam-pahafahana mampiasa ‘scanner’ ianao, dia afaka mampiasa ny OCR amin'ny alàlan'ny Google. Haingana kokoa ny asa
Wow. Searching Google Drive for a keyword also returns results for images containing that keyword in the image. Didn't realise it did OCR.
— Mark Osborne (@mosborne01) August 25, 2015
Oaaay, Ny fikarohana tenifototra amin'ny Google Drive koa dia mitondra ho amin'ireo sary miaty izany tenifototra izany ao anatin'ilay sary. Tena tsy tao an-tsaina mihitsy hoe hahavita izany ny OCR
Raha ny nahazatra dia sahirana ny OCR rehefa hamaky lahatsoratra tranainy be na pejy misy tsy fahatomombanana sy voapentin'ny ranomainty, ka lasa mamoaka teny tsy fantatra na zavatra tsy azo vakiana.
Ny pejy fanohanana ao amin'ny Google ho an'ity tetikasa ity dia mizara antsipirihany fanampiny momba ny fandrafetana ny endri-tsoratra, toy ny fahafahany mitahiry ny endrika matavy sy misompirana ao anatin'ny lahatsoratra hivoaka:
Rehefa mikarakara ny lahatsoratra, miezaka isika ny mitahiry ireo endrika fototra efa nandrafetantsika azy, toy ny soratra matavy sy misompirana, ny haben'ny tarehin-tsoratra sy ny karazany, ny fidinana an-dàlana. Kanefa, sarotra ny mitily ireny singa ireny ary mety tsy hotafitantska mandrakariva. Tahaka ny ho very ireo fomba hafa fandrafetana lahatsoratra sy fandaminana ny singa, toy ireo fitanisàna lisitra ialohavanà teboka sy tarehimarika, ny tsanganan-dahatsoratra sy ireo fanamarihana kely ery amin'ny faran'ny pejy.
Ho an'ireo fiteny sasantsasany, toy ny Malayalam sy Tamil, saiky 100% ny asa vita amin'ny OCR, ary ahitàna tohana ho amin'ny fandrafetana zavatra toy ny fanafohezana mandeha ho azy, fanasarahana lahatsoratra amin'ny alàlan'ny sary, ary ny tsy fandraisana ny loko natao lafika, hoy ny fanazavan'ireo mpampiasa ny Tamil sy ilay Wikimedian Ravishankar Ayyakkannu ao amin'ny Facebook:
[…] 100% ny asan'ny OCR Google Tamil ! Tohizo amin'ny fanandràmana ohatra samihafa ary apetraho eto ny fanehoankevitra. Mitovy ihany koa ny vokatra tamin'ireo famantarana ny fiteny maro hafa. […] Fanafohezana mandeha ho azy, Auto crops, fanesorana ireo sary sy loko natao lafika. Mamantatra mari-pamantarana endri-tsoratra isankarazany. Diso iray monja no hitako taminà pejy iray manontolo. Manandrana ny Vikatan farany indrindra – https://docs.google.com/…/1OXre4…/edit.. […]
(Samy naneho hevitra tao aminà lahatsoratra iray ihany ireo mpampiasa ny fiteny Bangla, Malayalam, Kannada, Odia, Tamil, sy Telugu-language, nanome domberina taorian'ny nanandramany ny rindrambaiko OCR efa nasiana fanavaozana. Ho an'ny soratra vitsivitsy, toy ny Gurmukhi ( zatra nanoratra ny Punjabi), toa tsikarira fa somary maivana/tsy ampy ihany ny zavatra navoakan'ny OCR, mamoaka zavatra tsy miteny, rehefa andramana amin'ny pikantsary avy ao amin'ny Punjabi Wikipedia.)
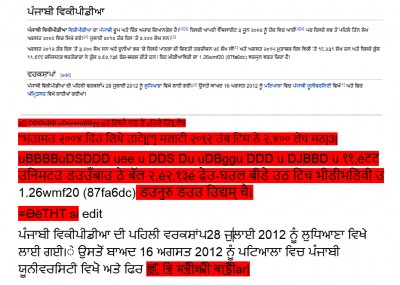
Ireo olana amin'ny soratra Gurmukhi taorian'ny nampiasàna ny OCR an'ny Google. Pikantsary tao amin'ny Punjabi Wikipedia.
Efa dingana goavana ihany aloha io ho an'ny ankamaroan'ireo fiteny manana lahatsoratra rakitry ny ela izay tsy mbola voatahiry amin'ny endriny dizitaly. Azo atao ankehitriny ny mitahiry ho amin'ny endrika dizitaly ireo lahatsoratra tranainy sy manana ny lanjany ary mizara azy ireny manerana ny aterineto amin'ny alàlan'ny fampiasàna ireo sehatra toy ny Wikisource, sady azo tahirizina sy atao azo idirana mba hifampizaràna fahalalàna.
Amin'ny ampahany ny OCR an'ny Google dia mampiasa ny Tesseract—milina OCR navoaka ho azo ampiasaina malalaka. Niarahana namolavola tamin'ny endrika tetikasanà vondrom-piaramonina, teo anelanean'ny 1995 sy 2006 (ary taty aoriana dia noraisin'ny Google an-tànana), azo heverina ho iray amin'ireo milina OCR azo itokiana indrindra eran'izao tontolo izao ny Tesseract ary mety ho an'ireo fiteny maherin'ny 60. Ao amin'ny https://github.com/tesseract-ocr no nampiantranoina ny loharanon'ilay rindrambaiko. Tsidiho ity rohy ity hijerena ireo vokatra navoakan'ny OCR avy amin'ireo soratra samihafa avy any Azia Atsimo.

Lahatsoratra notsongain-ny Rising Voices, tetikasa iray miaraka amin-ny Global Voices manampy amin-ny fanapariahana vaovaon-ny tsy mbola mahatakatra aterineto loatra ity. · Lahatsoratra rehetra





